📚 分类
集合
🕵🏽♀️ 问题描述
HashMap的寻址算法是什么?
👨🏫 问题讲解
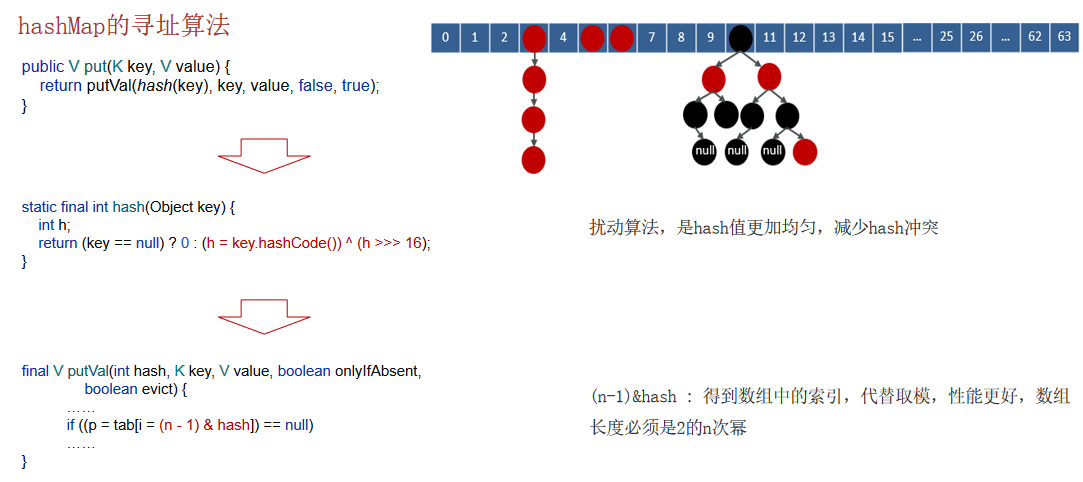
❒ Hash计算过程
// 1.Hash计算key
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 2.对Hash值右移16位再与原来的hash值做异或运算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 3.(n - 1) & hash:得到数组中的索引,代替取模,性能更好数组长度必须是2的n次幂
final V putVal(int hash, K key, V value, boolean onlylfAbsent, boolean evict) {
......
if ((p = tab[i = (n - 1) & hash]) == null)
......
}
❒ 为何HashMap的数组长度一定是2的次幂?
1.计算索引时效率更高:如果是2 的n次幂可以使用位与运算代替取模。
2.扩容时重新计算索引效率更高:hash & oldCap ==0的元素留在原来位置,否则新位置 = 旧位置 + oldCap。
🏳️🌈 问题总结
❒ HashMap的寻址算法? ✔ 计算对象的hashCode()。 ✔ 再进行调用hash()方法进行二次哈希,hashcode值右移16位再异或运算,让哈希分布更为均匀。 ✔ 最后(capacity- 1) & hash得到索引。 ❒ 为什么要无符号右移16位? ✔ 如果直接用 h 作为哈希结果,HashMap 会用 h & (数组长度-1) 计算下标。 ✔ 初始化数组长度通常远小于 2¹⁶(比如初始长度 16),这会导致只用到 h 的低 16 位,高 16 位完全浪费,容易出现哈希冲突(不同的 key 算出同一个下标)。 ❒ 为什么是右移16位,而不是别的长度? ✔ 因为int类型占4个字节,一个字节=8位,所以int类型的长度是32位。 ✔ 16 位是中点,能让全部高 16 位和低 16 位充分混合,是混合效果最好的选择。 ✔ 用无符号右移(>>>)而非有符号右移(>>),是为了保证正负哈希值的混合逻辑一致,避免额外冲突。 ❒ 为何HashMap的数组长度一定是2的次幂? ✔ 计算索引时效率更高:如果是2的n次幂可以使用位与运算代替取模。 ✔ 扩容时重新计算索引效率更高:hash & oldCap == 0 的元素留在原来位置,否则index = oldIndex + oldCap。
📖 问题信息
📈 浏览次数:19 |
📅 更新时间:2026-01-17 23:16:30
📦 创建信息
🏷️ ID:92 |
📅 创建时间:2024-11-19 23:23:12
